
Introduction:
The field of artificial intelligence–driven image synthesis has undergone rapid acceleration over the past few years. Every new iteration of generative models has attempted to refine visual fidelity, semantic understanding, and computational efficiency. Among these evolutionary milestones, the Stable Diffusion v2 Series remains one of the most discussed and analytically important architectures.
Originally introduced as an enhanced successor to Stable Diffusion 1.5, version 2 was designed to elevate realism, improve prompt interpretation, and deliver higher-resolution outputs. However, its journey was not entirely linear. Instead of universally replacing its predecessor, it created a divided ecosystem of users, developers, and digital artists.
Some creators praised its sharper structural consistency and improved photorealistic rendering. Others criticized its reduced stylistic flexibility and restrictive generative variance.
Even in 2026, Stable Diffusion v2 continues to hold relevance—not as the dominant generative engine, but as a transformational benchmark in AI diffusion model evolution.
In this comprehensive guide, you will explore:
- What Stable Diffusion v2 Series actually is
- How it functions at a conceptual and technical level
- Key features and architectural improvements
- Limitations and adoption challenges
- Comparative analysis with SD 1.5 and SDXL
- Real-world industry applications
- Advanced prompt engineering strategies
- Its relevance in modern AI workflows
Let’s begin this deep analytical breakdown.
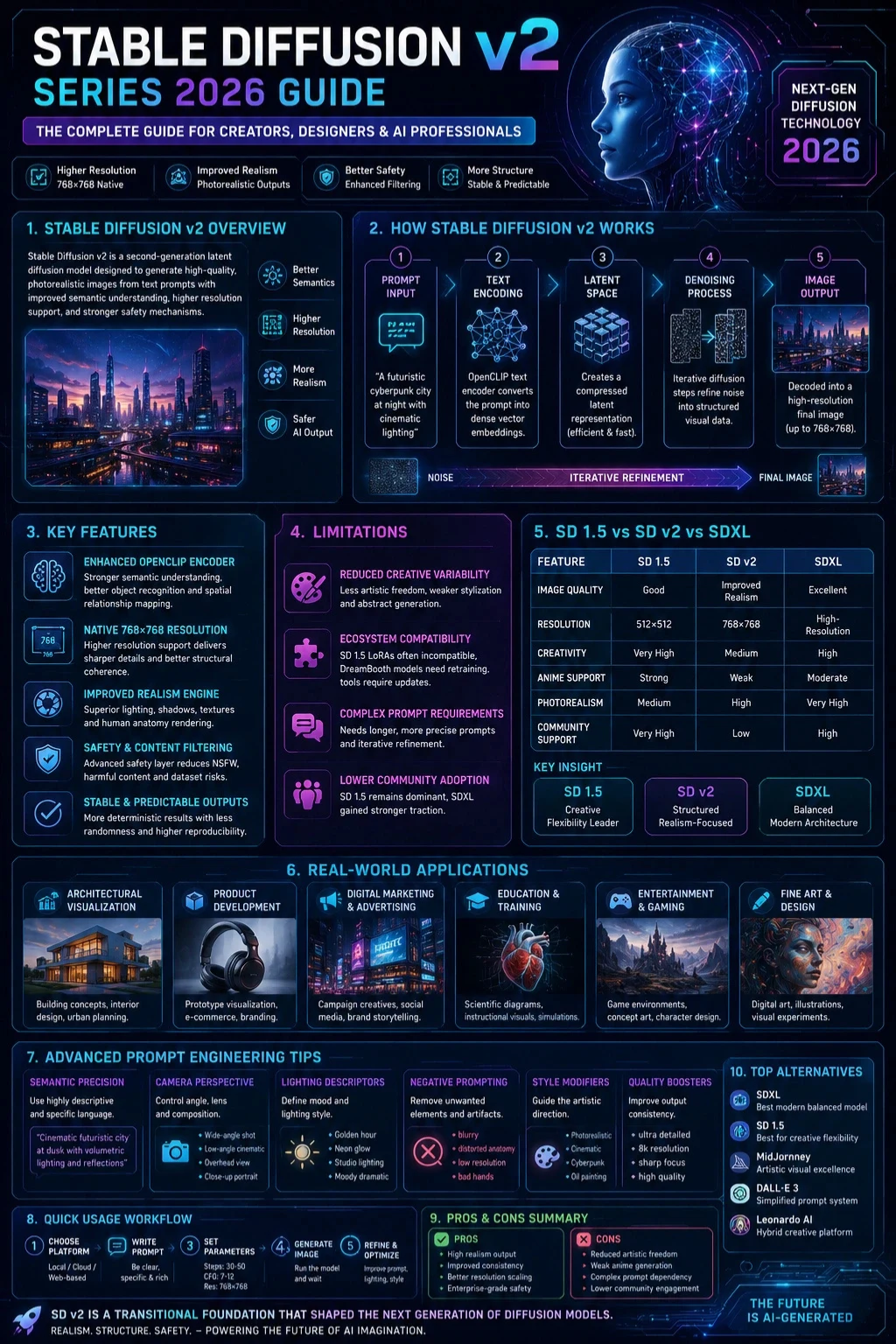
What is Stable Diffusion v2 Series?
The Stable Diffusion v2 Series is a second-generation latent diffusion-based generative model engineered to produce high-quality synthetic images from textual descriptions. It operates by transforming natural language prompts into structured visual outputs through probabilistic diffusion mechanisms.
Core Design Objectives of SD v2:
The architecture was specifically optimized to improve:
- Photorealistic rendering accuracy
- Semantic alignment between text and image
- Output resolution scalability
- Content safety and moderation control
It was developed to overcome limitations observed in Stable Diffusion 1.5, particularly:
- Restricted resolution ceiling (512×512 outputs)
- Weak contextual understanding of prompts
- Inconsistent human anatomy rendering
- Limited realism in lighting and texture modeling
Conceptual Foundation:
At its core, SD v2 aimed to create a balance between:
Visual fidelity + semantic comprehension + computational efficiency
However, this balance introduced trade-offs that significantly impacted creative flexibility.

How Stable Diffusion v2 Works
Understanding SD v2 does not require deep mathematical expertise. Instead, it can be interpreted through a structured generative pipeline.
Natural Language Prompt Encoding
When a user inputs a descriptive phrase such as:
“a futuristic cyberpunk city illuminated at night with cinematic lighting.”
The model converts this textual input into dense vector embeddings using an advanced text encoder (OpenCLIP-based architecture).
This process allows the system to interpret:
- Semantic meaning
- Contextual relationships
- Object-level associations
Latent Representation Formation
Instead of directly generating pixel-based images, SD v2 constructs a compressed latent space representation.
This technique significantly:
- Reduces computational overhead
- Improves generation speed
- Optimizes memory usage
Noise Initialization Phase
The generation process begins with a randomized noise matrix resembling static interference patterns.
Iterative Denoising Mechanism
Through multiple diffusion steps, the model progressively refines noise into structured visual data.
This stage is responsible for:
- Shape formation
- Texture Development
- Lighting simulation
- Object positioning
Final Image Decoding
The refined latent representation is decoded into a full-resolution image, producing the final visual output.

Key Features of Stable Diffusion v2
Enhanced OpenCLIP Language Encoder
One of the most significant improvements is the integration of a refined OpenCLIP-based encoder, enabling:
- Improved semantic interpretation
- Stronger object recognition accuracy
- Better spatial relationship mapping
- Higher prompt-to-image alignment
However, this improvement also introduced stricter interpretability constraints, limiting creative randomness.
Native Higher Resolution Support
SD v2 introduced native support for 768×768 image generation, compared to the 512×512 limitation of SD 1.5.
Benefits include:
- Sharper image detail density
- Enhanced edge clarity
- Improved structural coherence
Improved Photorealistic Rendering Engine
The model exhibits significant advancements in realism, particularly in:
- Lighting physics simulation
- Shadow depth accuracy
- Human facial structure refinement
- Environmental consistency
Safety and Content Filtering Layer
A reinforced safety architecture was integrated to minimize:
- NSFW outputs
- Harmful or biased content
- Dataset contamination risks
While beneficial for enterprise usage, it restricted open creative experimentation.
Stable and Predictable Output Behavior
Compared to earlier versions, SD v2 delivers:
- Reduced randomness
- Higher reproducibility
- More deterministic outputs
Limitations of Stable Diffusion v2
Despite technical improvements, SD v2 introduced several adoption barriers.
Reduced Creative Variability
The most criticized limitation is the reduction in artistic freedom.
Issues include:
- Weak stylization control
- Limited anime generation capability
- Reduced abstract creativity
Ecosystem Compatibility Issues
SD v2 disrupted existing workflows:
- SD 1.5 LoRA models are often incompatible
- DreamBooth models required retraining
- Community tools needed structural updates
Complex Prompt Engineering Requirements
Unlike SD 1.5, SD v2 requires:
- Longer descriptive prompts
- More precise semantic structuring
- Iterative refinement cycles
Lower Community Adoption Rate
Despite technical improvements:
- SD 1.5 remained widely dominant
- SDXL gained stronger traction
- SD v2 became a transitional model

Stable Diffusion v2 vs SD 1.5 vs SDXL
| Feature | SD 1.5 | SD v2 | SDXL |
| Image Quality | Good | Improved realism | Excellent |
| Resolution | 512×512 | 768×768 | High-resolution |
| Creativity | Very High | Medium | High |
| Anime Support | Strong | Weak | Moderate |
| Photorealism | Medium | High | Very High |
| Community Support | Very High | Low | High |
Key Insight:
- SD 1.5 → Creative flexibility leader
- SD v2 → Structured realism-focused model
- SDXL → Balanced modern architecture
Real-World Applications of Stable Diffusion v2
Despite reduced popularity, SD v2 remains relevant in professional workflows.
Architectural Visualization
Widely used in European markets such as Germany and France for:
- Building concept previews
- Interior spatial design
- Urban planning visualization
Product Development
Used in UK and EU industries for:
- Prototype visualization
- E-commerce product modeling
- Branding concept creation
Digital Marketing Agencies
Applied in:
- Advertising creatives
- Social Media Campaigns
- Brand storytelling visuals
Educational Content Design
Used for:
- Scientific diagrams
- Instructional visuals
- Training simulations
Step-by-Step Usage Guide
Select Platform
Options include:
- Local GPU installation
- Cloud-based AI services
- Web-based generators
Prompt Construction
Example:
“a cinematic futuristic skyline at dusk, ultra realistic, volumetric lighting, wide-angle perspective”
Parameter Configuration
Recommended settings:
- Steps: 30–50
- CFG Scale: 7–12
- Resolution: 768×768
Image Generation
Execute the rendering process and wait for output completion.
Optimization Loop
Refine results using:
- Enhanced descriptive language
- Lighting adjustments
- Style modifiers
Advanced Prompt Engineering Techniques
To maximize output quality:
Semantic Precision
Use highly descriptive language instead of generic terms.
Camera Perspective Control
- wide-angle
- macro shot
- low-angle cinematic
Lighting Descriptors
- golden hour
- neon glow
- studio lighting setup
Negative Prompting
Exclude unwanted artifacts:
- blurry
- distorted anatomy
- low resolution
Pros and Cons Summary
Advantages:
- High realism output
- Improved structural consistency
- Better resolution scaling
- Enterprise-grade safety
Disadvantages:
- Reduced artistic flexibility
- Weak anime generation
- Complex prompt dependency
- Lower community engagement
Alternatives to Stable Diffusion v2
- SD 1.5 → creative workflows
- SDXL → modern balanced model
- MidJourney → artistic visuals
- DALL·E 3 → simplified prompt system
- Leonardo AI → hybrid creative platform
FAQs
It offers better realism but reduced creative flexibility.
Due to limited artistic freedom and compatibility issues.
It performs poorly in anime generation compared to SD 1.5.
Yes, it is open-source, though platforms may charge for hosting.
Stable Diffusion XL and MidJourney are more widely adopted.
Conclusion
Stable Diffusion v2 represents a crucial evolutionary stage in generative AI history. It successfully improved realism, Structural Accuracy, and safety mechanisms, but simultaneously reduced creative freedom and ecosystem compatibility.
In modern AI workflows:
- Professionals still use it for structured outputs
- Artists prefer more flexible models
- SDXL dominates contemporary production pipelines
In essence, SD v2 is not obsolete—it is a transitional foundation that shaped the next generation of diffusion models.










